

AI Agents Are Writing Your Code Now. The Real Skill Is Reviewing It.


Apr 10, 20268 min read
Stripe Is What Software Is Supposed to Feel Like
Not a love letter. An investigation. Stripe's documentation, API design, and developer experience se...
Devesh Korde
March 18, 2026
You have used Angular Router a hundred times. You define routes, add RouterModule, throw in a routerLink, and it works. But have you ever stopped and asked what actually happens between the moment a URL changes and the moment your component appears on screen?
Most tutorials stop at the API. This one starts where they stop.
This is the first thing nobody tells you. The Angular Router is not just a URL matcher. It is a full state machine with defined phases, and it moves through each phase in a strict, predictable order every single time a navigation happens.
When you call navigate, click a routerLink, or type a URL directly into the browser, the router kicks off a pipeline. That pipeline has exactly six phases — URL Recognition, Redirects, Guard Execution, Resolvers, Activation, and Final URL Update. Every navigation goes through all six, in that order, no exceptions.
Miss this mental model and the router will always feel like magic. Understand it and you can predict exactly what will happen, when, and why.
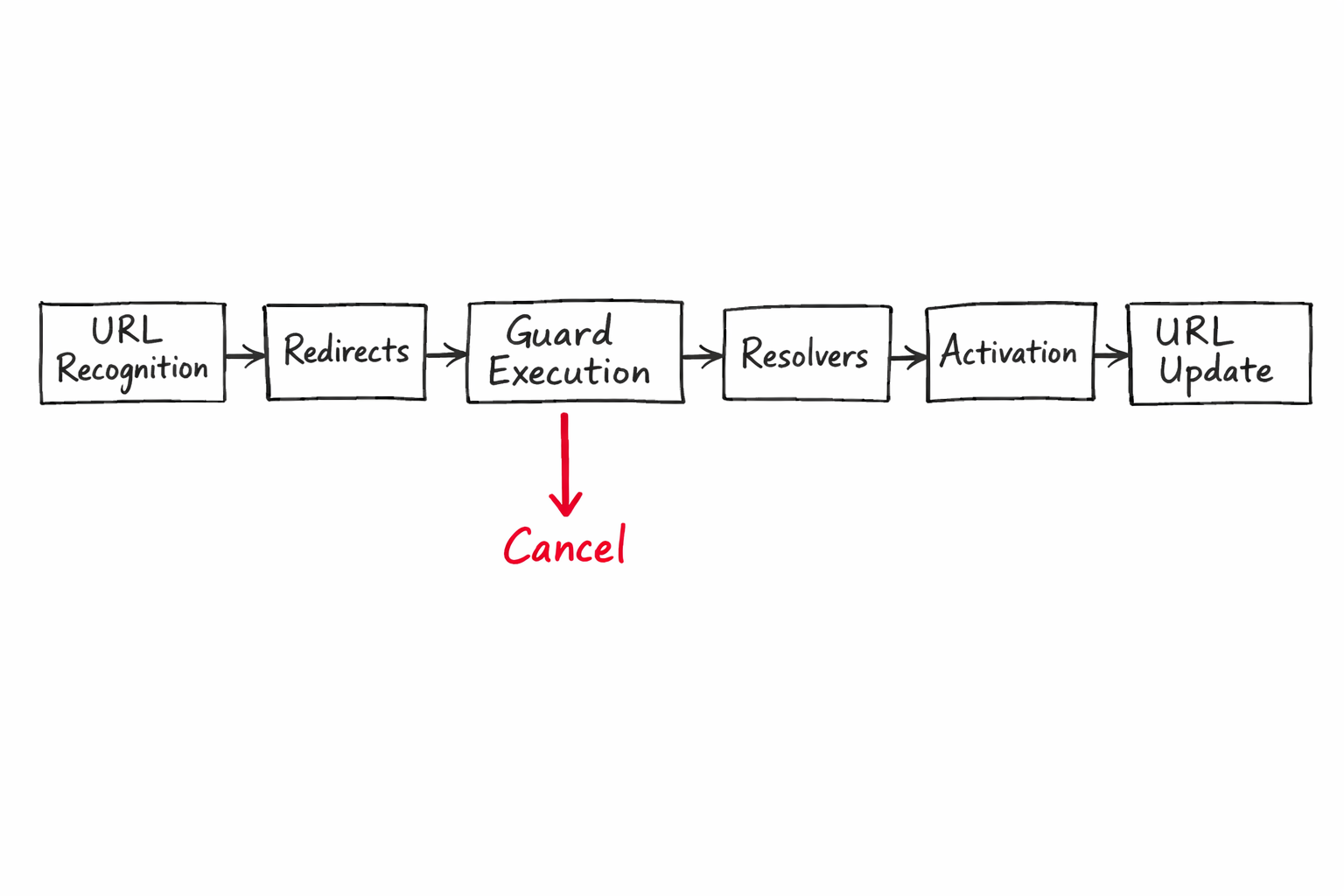
The first thing the router does is parse the incoming URL into a data structure called a UrlTree. A UrlTree is not a string. It is an object that represents the full hierarchical structure of the URL — including the primary outlet, any named outlets, path segments, matrix parameters, and query parameters — all structured as a tree.
The class responsible for this parsing is called DefaultUrlSerializer. It implements a UrlSerializer interface, which means you can completely replace URL parsing logic by providing your own implementation. Most developers never need this, but knowing it exists tells you something important — the router treats URL parsing as a pluggable concern, not hardcoded behavior.
After the UrlTree is built, the router runs it through the RouteRecognizer. This is where your routes array is matched against the parsed URL tree. The recognizer walks your routes depth-first and tries to match each segment. When it finds a complete match it builds another data structure called a RouterStateSnapshot.
A RouterStateSnapshot is a tree of ActivatedRouteSnapshots. Each node represents one matched route. This snapshot is immutable — it is a frozen picture of what the router state would look like if navigation succeeds. Nothing has changed in the app yet. The router is just planning.
Before any guard runs, the router applies all redirects. This happens at the RouterStateSnapshot level, not the raw URL level. The router evaluates your redirectTo rules against the already-matched route segments.
The pathMatch full option tells the recognizer to only trigger a redirect if the entire URL is consumed by that route, not just a prefix. This distinction is the source of one of the most common Angular bugs developers hit. A redirect with pathMatch prefix will fire even if there are more segments after the matched part. A redirect with pathMatch full only fires when the URL is completely consumed.
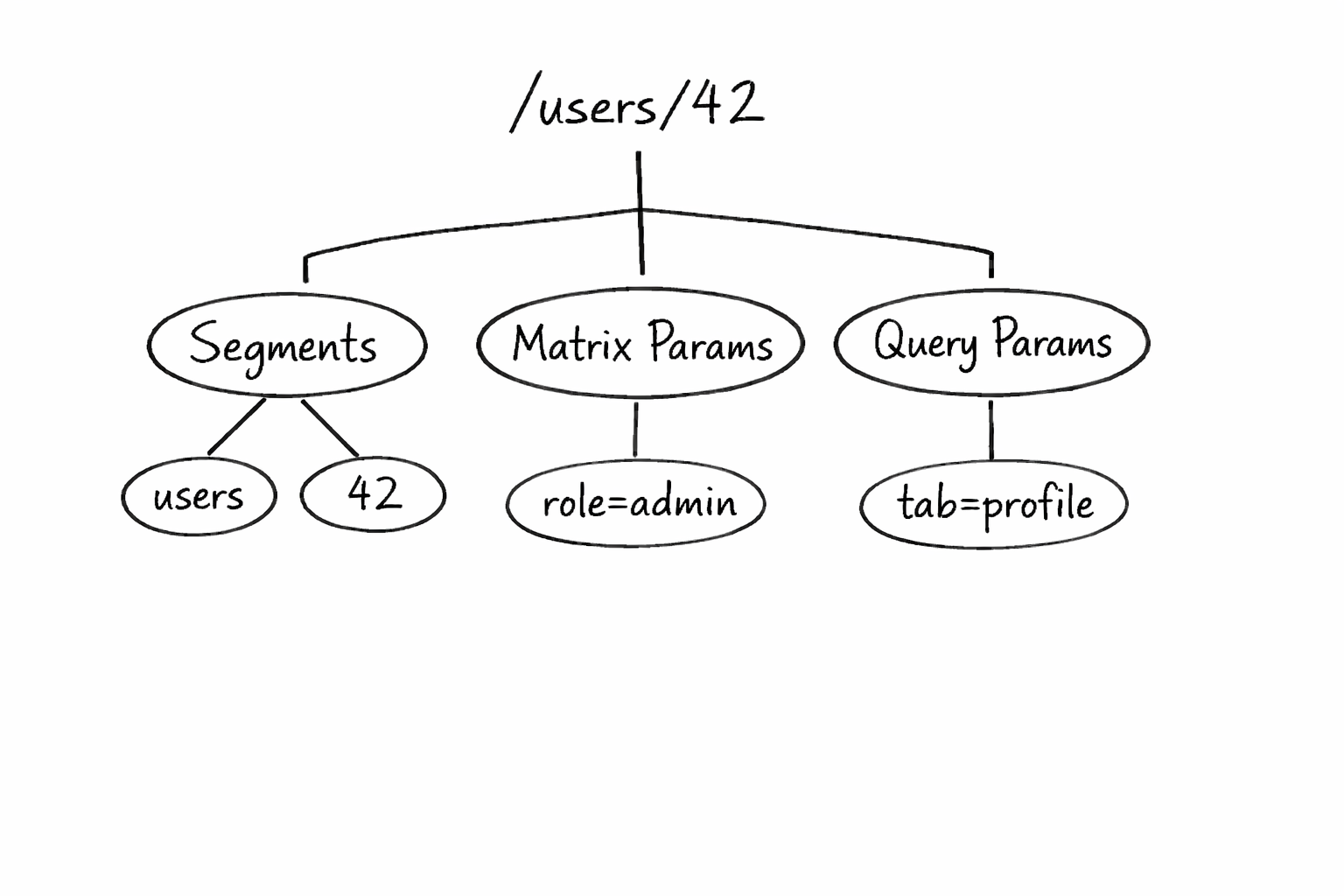
Here is where most explanations fail. Guards are not just boolean checks. They are observables that the router subscribes to in a very specific order, and that order is not arbitrary.
The router runs guards in this exact sequence — CanDeactivate first, then CanActivateChild, then CanActivate, then CanLoad. This order reflects a logical priority. You check whether you can leave before you check whether you can enter. You check parent-level child permissions before route-level permissions.
The deeper internal truth is that every guard return type — whether you return a plain boolean, a Promise, or an Observable — is normalized to an Observable by the router before it is evaluated. The router calls an internal wrapIntoObservable function on whatever you return. This is why all three return types work correctly. The router does not care which you use. It converts them all to the same thing before proceeding.
If any guard returns false, navigation is cancelled immediately. If a guard returns a UrlTree instead of a boolean, the router treats that UrlTree as a redirect target and starts a new navigation to that URL. This is the cleanest way to implement guard-based redirects and almost nobody knows it works this way.
Resolvers run only after all guards have passed. Their job is to pre-fetch data so that when your component is created, all the data it needs already exists. The component never has to deal with an empty or loading state caused by missing route data.
What most developers do not realise is that resolvers block navigation. The router does not create your component until every resolver attached to that route emits its first value and completes. This is intentional by design.
There is a subtlety in how resolvers run across a route tree. Resolvers on the same route level run in parallel — the router does not wait for one before starting another at the same level. But parent resolvers must fully complete before child resolvers start. This mirrors the tree structure of the RouterStateSnapshot and ensures that child routes always have access to resolved parent data if they need it.
The resolved data ends up in two places — in ActivatedRoute snapshot data as a plain object you can read immediately, and in ActivatedRoute data as an Observable that emits on every navigation to that route.
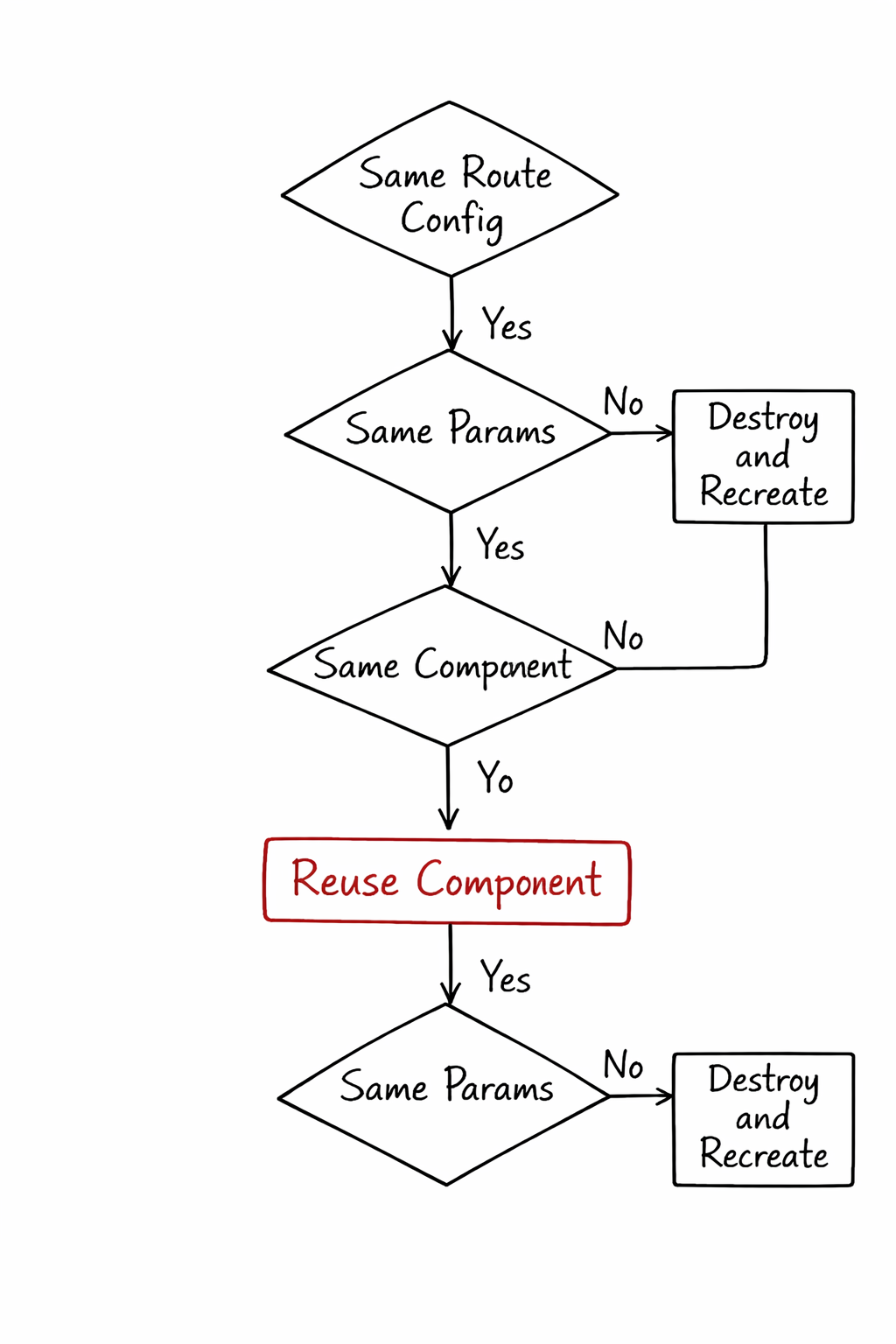
This is the most misunderstood phase. After guards pass and resolvers complete, the router compares the current live RouterState with the new RouterStateSnapshot it built in Phase 1. It walks both trees simultaneously and for each node asks three questions — is this the same route config, are the params the same, and is the component the same?
If all three match, the existing component instance is reused. No destroy lifecycle, no create lifecycle, no ngOnInit. The component stays alive and only the ActivatedRoute observables emit new values.
This is a critical internal detail that explains a bug many Angular developers hit and never understand. If you navigate from one user profile to another — say from user 1 to user 2 — and you are reading the ID only from the route snapshot in ngOnInit, you will get stale data. The component is reused, ngOnInit does not run again, and your snapshot still shows the old ID. The fix is to subscribe to the params Observable instead of reading the snapshot, so your component reacts every time the params change even when the component instance stays the same.
If the component does need to be replaced, the router calls the outlet's deactivate method which destroys the old component and then calls activate which creates the new one. RouterOutlet is just a host element that delegates creation and destruction to the component factory infrastructure.
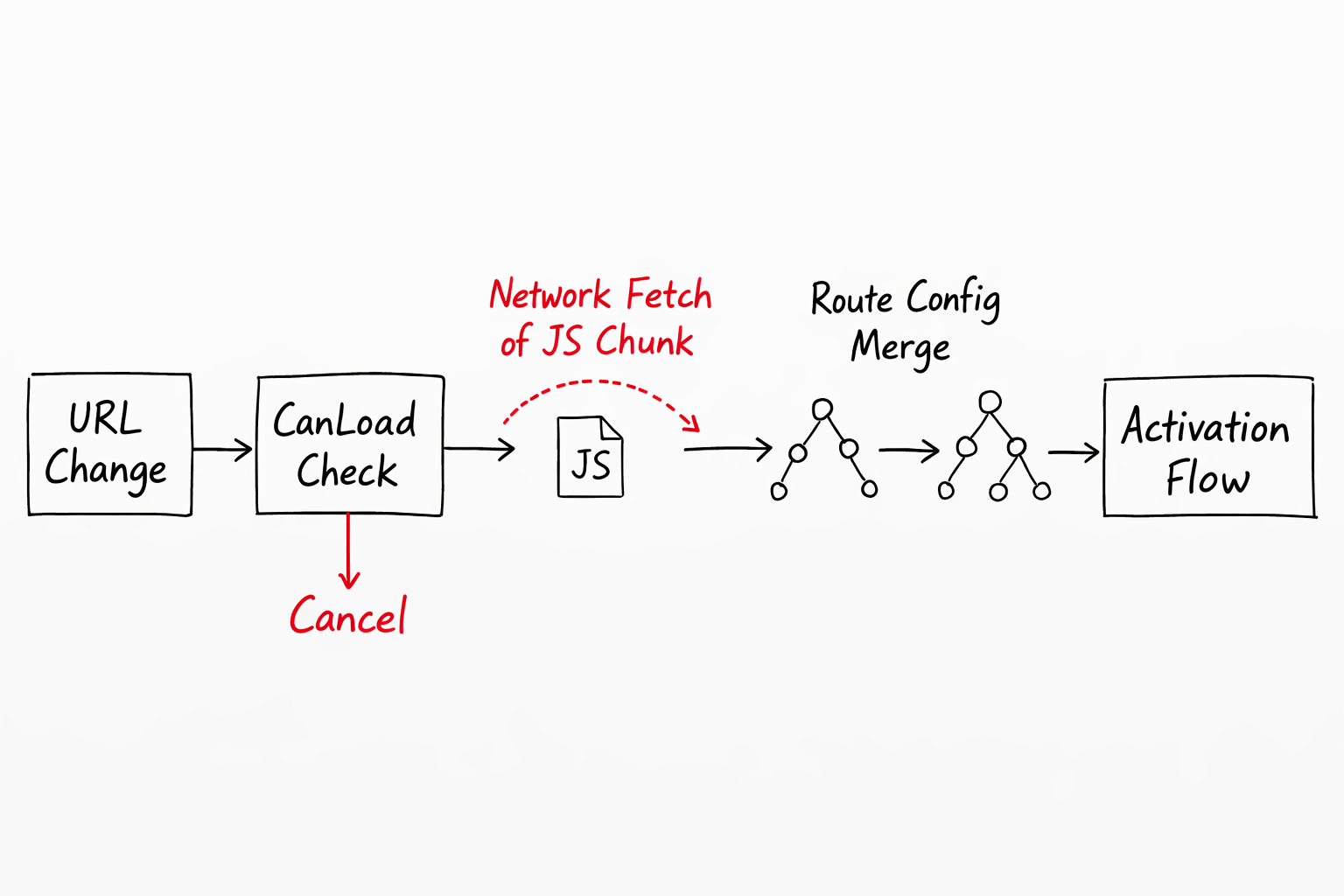
Lazy loading is where the router does its most impressive internal work. When you define a lazy route using loadChildren, the function you provide is not called when the app boots. The entire module is not fetched, not parsed, not instantiated. It simply does not exist in the browser yet.
The loadChildren function is called during the CanLoad phase — before CanActivate runs for that route. This is what makes CanLoad fundamentally different from CanActivate. CanActivate runs after the module is already loaded. CanLoad runs before the browser even fetches it. If your CanLoad guard returns false, the network request for that module never happens. This is the correct guard to use when you want to truly hide a feature from unauthorised users, not just block access to it.
Once CanLoad passes, the router calls the loadChildren function which returns a dynamic import Promise. The browser fetches the JavaScript chunk over the network. Once it arrives, Angular's compiler processes the module's route config and merges it into the existing router configuration at runtime. The router then continues navigation as if those routes had always existed.
This merge happens through the RouterConfigLoader class internally. It takes the loaded module, extracts its routes, and calls resetConfig on the router to add them into the live route tree. From that point on, the lazy routes behave identically to eagerly loaded routes.
There is one more internal concept worth understanding. The router exposes a NavigationEvents Observable on the Router service that fires an event for every phase transition. Most developers only use this to show a loading spinner, but it tells you far more than that.
NavigationStart fires when the pipeline begins. RoutesRecognized fires after Phase 1 completes. GuardsCheckStart and GuardsCheckEnd bracket Phase 3. ResolveStart and ResolveEnd bracket Phase 4. ActivationStart and ActivationEnd bracket Phase 5. NavigationEnd fires when the URL is finally committed. NavigationCancel fires if any guard cancels navigation. NavigationError fires if something throws.
Subscribing to this stream and logging every event is the single most effective way to understand what the router is actually doing during a navigation. It turns the black box into a transparent pipeline.
Understanding router internals is not just academic. It directly explains why component reuse means you must subscribe to param observables. It explains why CanLoad is the right guard for security-sensitive lazy routes. It explains why resolvers block rendering and when that is a feature versus a problem. It explains why guard order matters and how to use UrlTree returns to redirect cleanly.
The Angular Router is one of the most sophisticated pieces of the framework. Most developers use 10 percent of what it actually does. The other 90 percent is not hidden — it is just never explained.

